COMPOSITIO: Arthistoric Analysis of Architecture via Computer Vision (2013-2015)
Björn Ommer, Peter Bell and Michael Arnold
Innovation Fund FRONTIER, Heidelberg University funded by German Research Foundation (DFG)
The interdisciplinary Frontier project connects computer vision with the field of art history and analyses early modern architecture with the help of machine learning and image processing. Our approach is initially based on a small database of 1324 images. The collection contains photographs of early modern facades, illustrations from architectural treatises, as well as drawings, and book illustrations from the British Library.
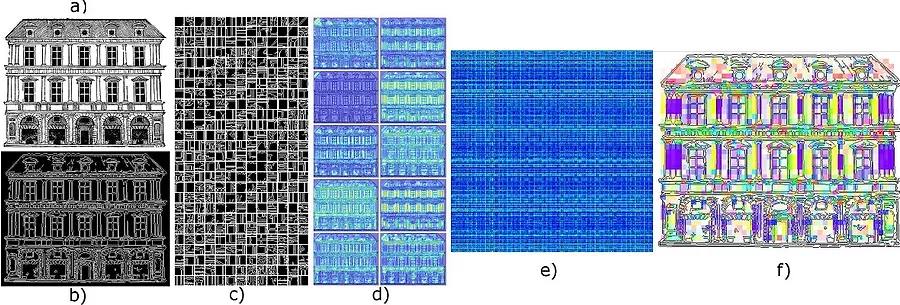
The Frontier project divides its research into three tasks. The first task is to detect entire buildings or parts of buildings. This is done either by selecting a part of an existing image or by uploading a new image. An offline pool of prototypical negative examples of early modern architecture can be created on the database (e.g. background images and non-objective parts of the image). This procedure requires little effort and allows the user to search for a larger scope of different details. Every search request performed by the user is then compared to the negative pool to identify its differences in order to find more similar objects in the image database.
For this project, we have designed a web-application to allow users easy access. Significant objects like balustrades, capitals, arches and sculptures are mostly well recognized and found, however, several mistakes may occur due to distracting geometrical forms or clutter present in the images.To further enhance the search results a new feature involves an interactive learning approach in which the user judges the search results according to the amount of similarities with the original search request. This trains the program to further specify the search request which increases the amount of suitable results. The second task consists of separately training significant architectural elements. An increasing number of trained objects enables the algorithm to recognize the requested category more precisely. The third task is the analysis of architecture by self-similarity. Unlike the first approach, this task is supposed to be solved without any learned input. With the help of Chamfer Matching, the algorithm identifies the shapes inside the image and compares similar patches in other images to find matching regions. This approach should not only be able to recognize and show similar parts of buildings but also allow for a deeper understanding of their composition and design. There is some evidence that, in comparison to other picture databases, working with images of architecture is not as easy as had been previously assumed. The unsupervised approach is especially challenging for basic research.