Deep generative models have matured to the point where they are transforming the way we create visual content. We explore powerful generative approaches such as Invertible Neural Networks, autoregressive Transformers, and Diffusion Models. We investigate their specific limitations to develop novel strategies that unleash the full potential of these architectures. Among others, this led to latent approaches such as VQGAN and Stable Diffusion and the disentanglement of shape and appearance in V-UNET. Our long-standing goal is to develop algorithms that make images accessible on a semantic level to simplify our interaction with computers and to democratize the availability of this enabling technology.
Selected Publications
2022
Blattmann, Andreas; Rombach, Robin; Oktay, Kaan; Ommer, Björn
Retrieval-Augmented Diffusion Models Conference
Neural Information Processing Systems (NeurIPS), 2022., 2022.
@conference{nokey,
title = {Retrieval-Augmented Diffusion Models},
author = {Andreas Blattmann and Robin Rombach and Kaan Oktay and Björn Ommer},
url = {https://arxiv.org/abs/2204.11824},
year = {2022},
date = {2022-01-01},
urldate = {2022-01-01},
booktitle = {Neural Information Processing Systems (NeurIPS), 2022.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
Rombach, Robin; Blattmann, Andreas; Ommer, Björn
Text-Guided Synthesis of Artistic Images with Retrieval-Augmented Diffusion Models Conference
Proceedings of the European Conference on Computer Vision (ECCV) Workshop on Visart, 2022.
@conference{nokey,
title = {Text-Guided Synthesis of Artistic Images with Retrieval-Augmented Diffusion Models},
author = {Robin Rombach and Andreas Blattmann and Björn Ommer},
url = {https://arxiv.org/abs/2207.13038},
year = {2022},
date = {2022-01-01},
urldate = {2022-01-01},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV) Workshop on Visart},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
Rombach, Robin; Blattmann, Andreas; Lorenz, Dominik; Esser, Patrick; Ommer, Björn
High-Resolution Image Synthesis with Latent Diffusion Models Conference
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
@conference{nokey,
title = {High-Resolution Image Synthesis with Latent Diffusion Models},
author = {Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
url = {https://ommer-lab.com/research/latent-diffusion-models/
https://github.com/CompVis/latent-diffusion
https://arxiv.org/abs/2112.10752},
year = {2022},
date = {2022-01-01},
urldate = {2022-01-01},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
2021
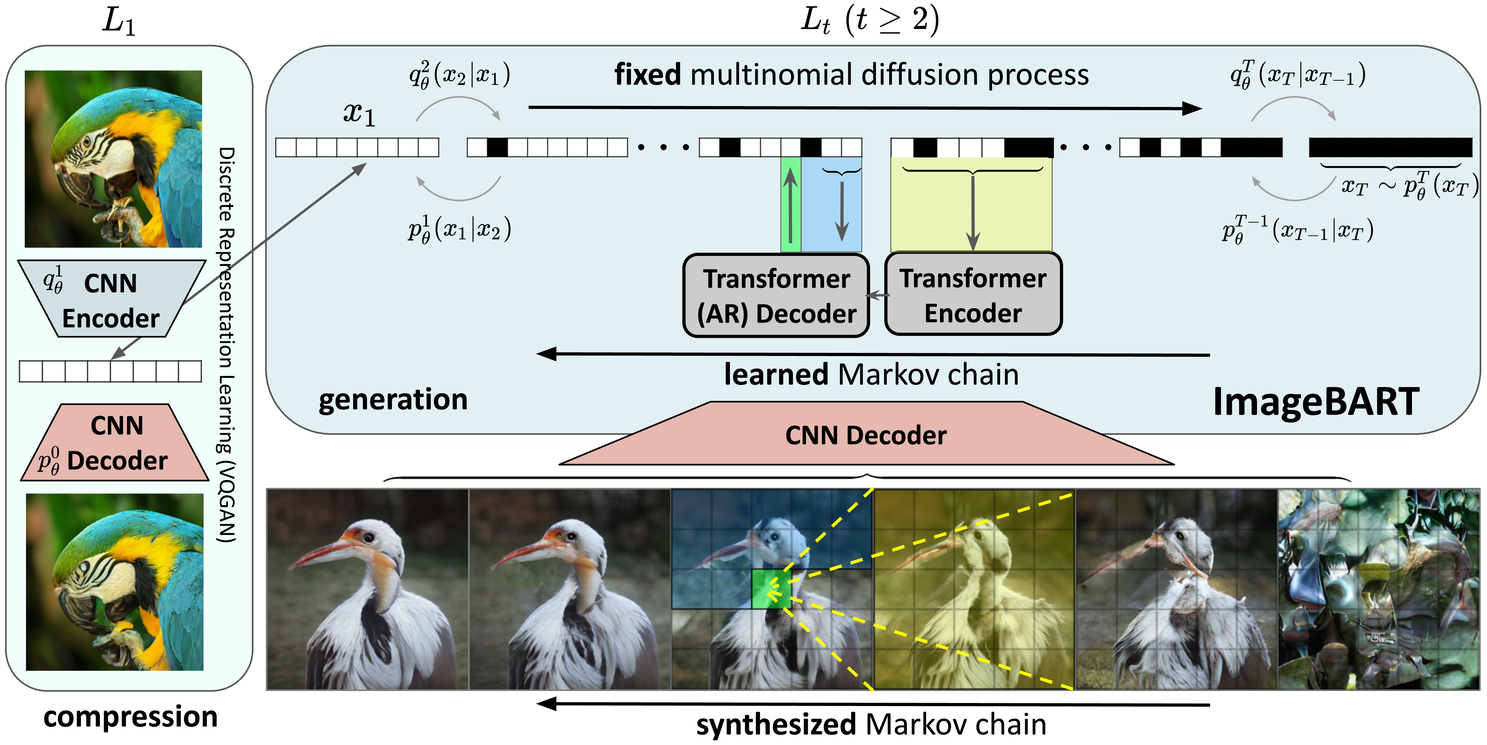
Esser, Patrick; Rombach, Robin; Blattmann, Andreas; Ommer, Björn
ImageBART: Bidirectional Context with Multinomial Diffusion for Autoregressive Image Synthesis Conference
Neural Information Processing Systems (NeurIPS), 2021.
@conference{nokey,
title = {ImageBART: Bidirectional Context with Multinomial Diffusion for Autoregressive Image Synthesis},
author = {Patrick Esser and Robin Rombach and Andreas Blattmann and Björn Ommer},
url = {https://compvis.github.io/imagebart/
https://arxiv.org/abs/2108.08827},
year = {2021},
date = {2021-12-10},
urldate = {2021-12-10},
booktitle = {Neural Information Processing Systems (NeurIPS)},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
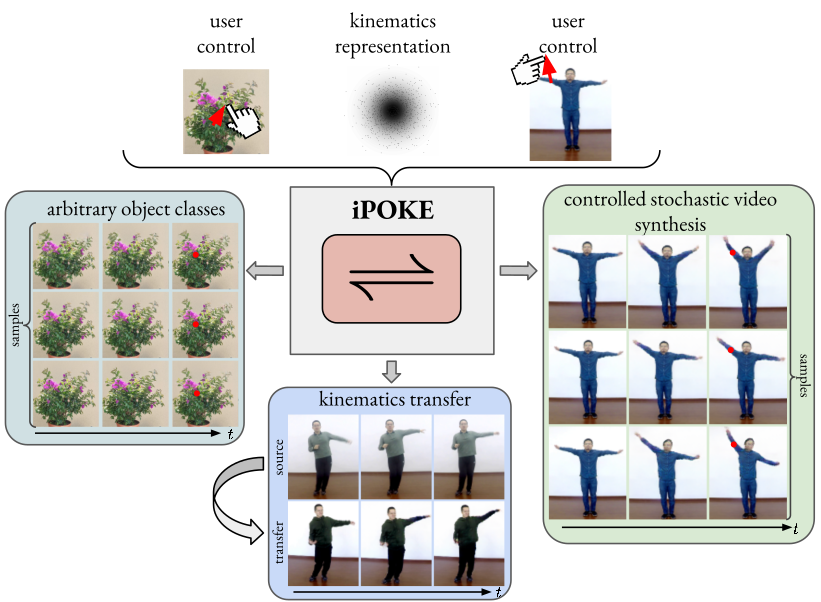
Blattmann, Andreas; Milbich, Timo; Dorkenwald, Michael; Ommer, Björn
iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis Conference
Proceedings of the International Conference on Computer Vision (ICCV), 2021.
@conference{Blattmann2021,
title = {iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis},
author = {Andreas Blattmann and Timo Milbich and Michael Dorkenwald and Björn Ommer},
url = {https://compvis.github.io/ipoke/
https://arxiv.org/abs/2107.02790},
year = {2021},
date = {2021-10-01},
urldate = {2021-10-01},
booktitle = {Proceedings of the International Conference on Computer Vision (ICCV)},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
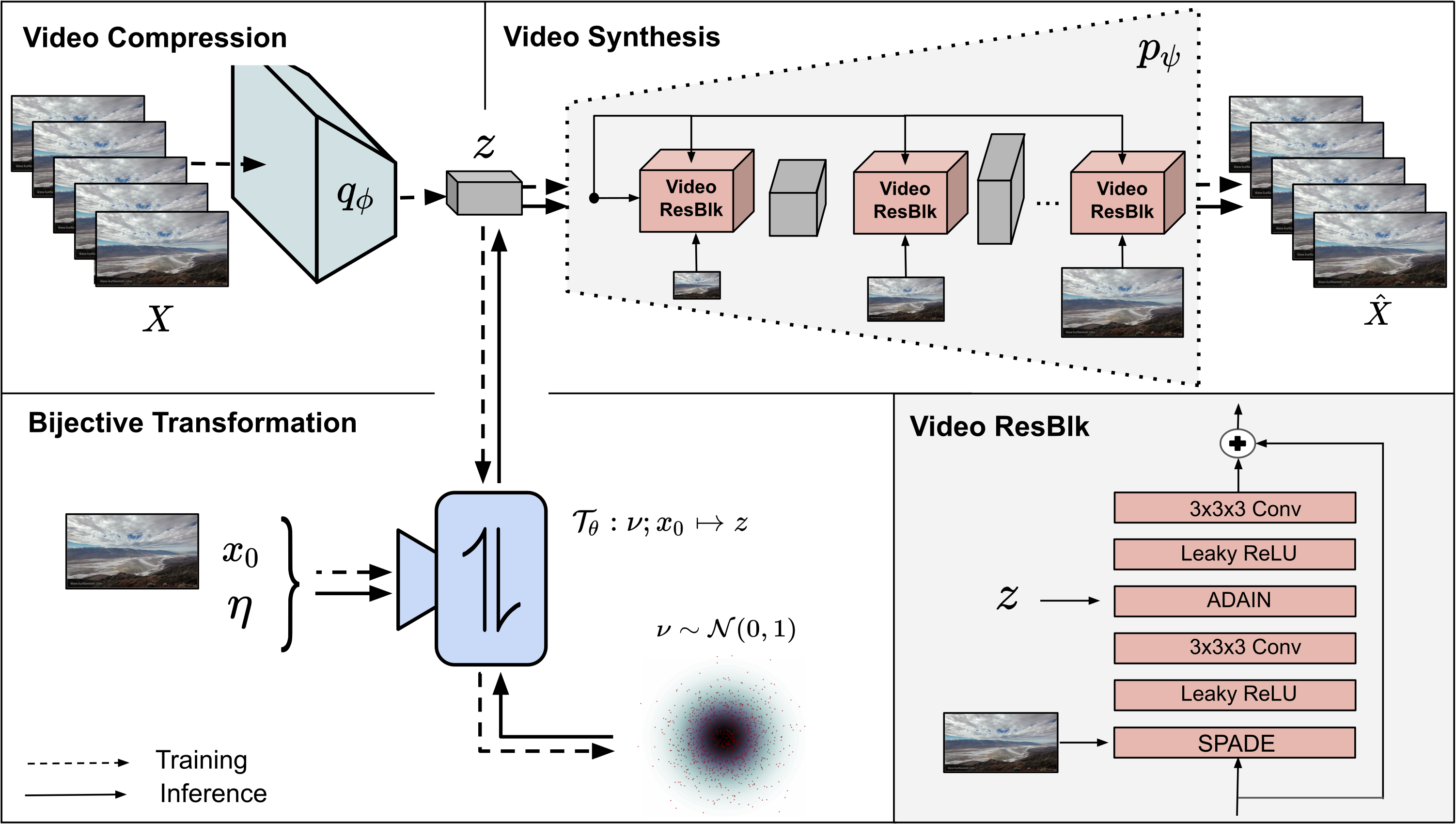
Dorkenwald, Michael; Milbich, Timo; Blattmann, Andreas; Rombach, Robin; Derpanis, Konstantinos G.; Ommer, Björn
Stochastic Image-to-Video Synthesis using cINNs Conference
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
@conference{7053,
title = {Stochastic Image-to-Video Synthesis using cINNs},
author = {Michael Dorkenwald and Timo Milbich and Andreas Blattmann and Robin Rombach and Konstantinos G. Derpanis and Björn Ommer},
url = {https://compvis.github.io/image2video-synthesis-using-cINNs/
https://arxiv.org/abs/2105.04551},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
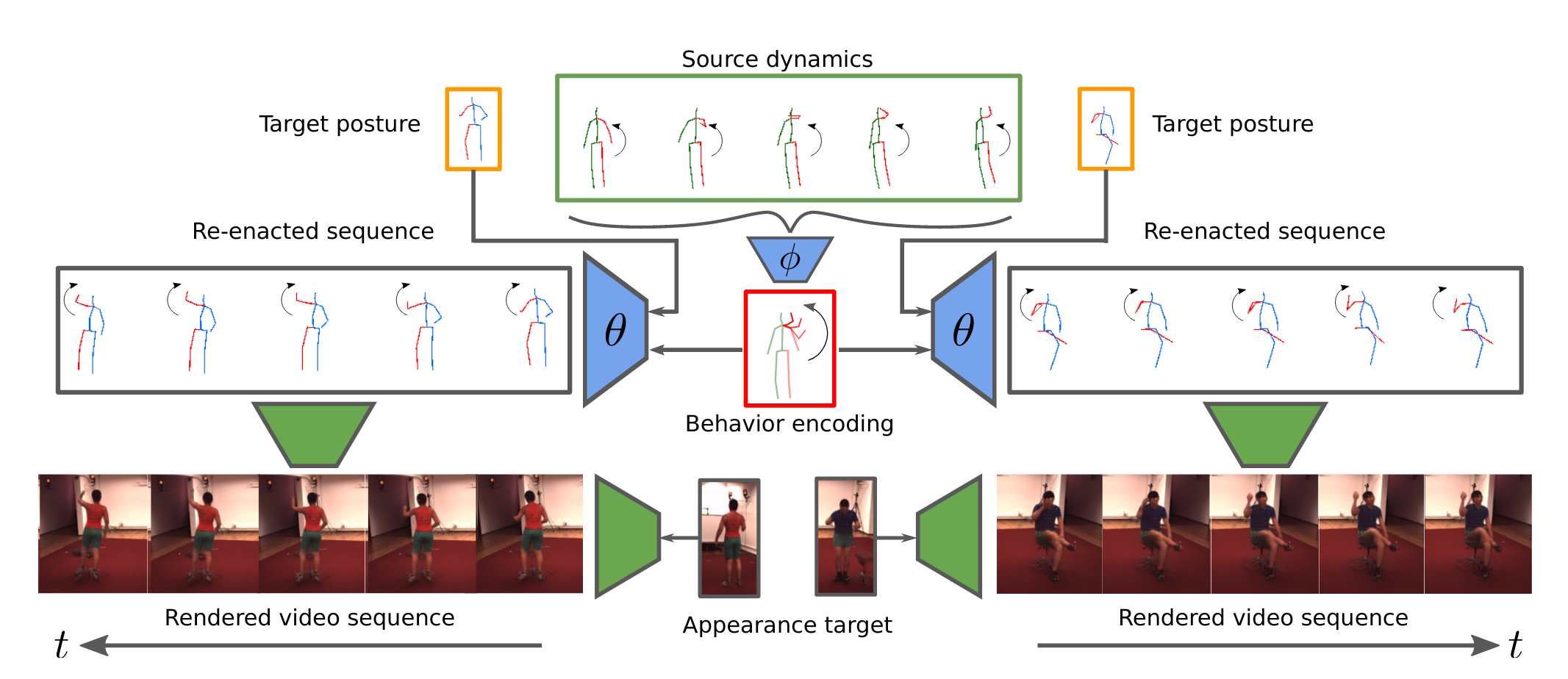
Blattmann, Andreas; Milbich, Timo; Dorkenwald, Michael; Ommer, Björn
Behavior-Driven Synthesis of Human Dynamics Conference
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
@conference{7044,
title = {Behavior-Driven Synthesis of Human Dynamics},
author = {Andreas Blattmann and Timo Milbich and Michael Dorkenwald and Björn Ommer},
url = {https://compvis.github.io/behavior-driven-video-synthesis/
https://arxiv.org/abs/2103.04677},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}

Esser, Patrick; Rombach, Robin; Ommer, Björn
Taming Transformers for High-Resolution Image Synthesis Conference
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
@conference{7028,
title = {Taming Transformers for High-Resolution Image Synthesis},
author = {Patrick Esser and Robin Rombach and Björn Ommer},
url = {https://compvis.github.io/taming-transformers/
https://arxiv.org/abs/2012.09841},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}

Rombach, Robin; Esser, Patrick; Ommer, Björn
Geometry-Free View Synthesis: Transformers and no 3D Priors Conference
Proceedings of the Intl. Conf. on Computer Vision (ICCV), 2021.
@conference{7067,
title = {Geometry-Free View Synthesis: Transformers and no 3D Priors},
author = {Robin Rombach and Patrick Esser and Björn Ommer},
url = {https://compvis.github.io/geometry-free-view-synthesis/
https://arxiv.org/abs/2104.07652},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
booktitle = {Proceedings of the Intl. Conf. on Computer Vision (ICCV)},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
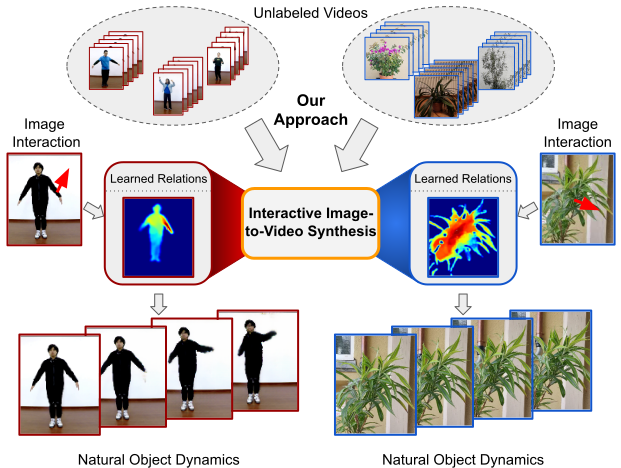
Blattmann, Andreas; Milbich, Timo; Dorkenwald, Michael; Ommer, Björn
Understanding Object Dynamics for Interactive Image-to-Video Synthesis Conference
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
@conference{7063,
title = {Understanding Object Dynamics for Interactive Image-to-Video Synthesis},
author = {Andreas Blattmann and Timo Milbich and Michael Dorkenwald and Björn Ommer},
url = {https://compvis.github.io/interactive-image2video-synthesis/
https://arxiv.org/abs/2106.11303v1},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
abstract = {What would be the effect of locally poking a static scene? We present an approach that learns naturally-looking global articulations caused by a local manipulation at a pixel level. Training requires only videos of moving objects but no information of the underlying manipulation of the physical scene. Our generative model learns to infer natural object dynamics as a response to user interaction and learns about the interrelations between different object body regions. Given a static image of an object and a local poking of a pixel, the approach then predicts how the object would deform over time. In contrast to existing work on video prediction, we do not synthesize arbitrary realistic videos but enable local interactive control of the deformation. Our model is not restricted to particular object categories and can transfer dynamics onto novel unseen object instances. Extensive experiments on diverse objects demonstrate the effectiveness of our approach compared to common video prediction frameworks.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}

Brattoli, Biagio; Büchler, Uta; Dorkenwald, Michael; Reiser, Philipp; Filli, Linard; Helmchen, Fritjof; Wahl, Anna-Sophia; Ommer, Björn
Unsupervised behaviour analysis and magnification (uBAM) using deep learning Journal Article
In: Nature Machine Intelligence, 2021.
@article{7045,
title = {Unsupervised behaviour analysis and magnification (uBAM) using deep learning},
author = {Biagio Brattoli and Uta Büchler and Michael Dorkenwald and Philipp Reiser and Linard Filli and Fritjof Helmchen and Anna-Sophia Wahl and Björn Ommer},
url = {https://utabuechler.github.io/behaviourAnalysis/
https://rdcu.be/ch6pL},
doi = {https://doi.org/10.1038/s42256-021-00326-x},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
journal = {Nature Machine Intelligence},
abstract = {Motor behaviour analysis is essential to biomedical research and clinical diagnostics as it provides a non-invasive strategy for identifying motor impairment and its change caused by interventions. State-of-the-art instrumented movement analysis is time- and cost-intensive, because it requires the placement of physical or virtual markers. As well as the effort required for marking the keypoints or annotations necessary for training or fine-tuning a detector, users need to know the interesting behaviour beforehand to provide meaningful keypoints. Here, we introduce unsupervised behaviour analysis and magnification (uBAM), an automatic deep learning algorithm for analysing behaviour by discovering and magnifying deviations. A central aspect is unsupervised learning of posture and behaviour representations to enable an objective comparison of movement. Besides discovering and quantifying deviations in behaviour, we also propose a generative model for visually magnifying subtle behaviour differences directly in a video without requiring a detour via keypoints or annotations. Essential for this magnification of deviations, even across different individuals, is a disentangling of appearance and behaviour. Evaluations on rodents and human patients with neurological diseases demonstrate the wide applicability of our approach. Moreover, combining optogenetic stimulation with our unsupervised behaviour analysis shows its suitability as a non-invasive diagnostic tool correlating function to brain plasticity.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Jahn, Manuel; Rombach, Robin; Ommer, Björn
High-Resolution Complex Scene Synthesis with Transformers Conference
CVPR 2021, AI for Content Creation Workshop, 2021.
@conference{7054,
title = {High-Resolution Complex Scene Synthesis with Transformers},
author = {Manuel Jahn and Robin Rombach and Björn Ommer},
url = {https://compvis.github.io/taming-transformers/
https://arxiv.org/abs/2105.06458},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
booktitle = {CVPR 2021, AI for Content Creation Workshop},
abstract = {The use of coarse-grained layouts for controllable synthesis of complex scene images via deep generative models has recently gained popularity. However, results of current approaches still fall short of their promise of high-resolution synthesis. We hypothesize that this is mostly due to the highly engineered nature of these approaches which often rely on auxiliary losses and intermediate steps such as mask generators. In this note, we present an orthogonal approach to this task, where the generative model is based on pure likelihood training without additional objectives. To do so, we first optimize a powerful compression model with adversarial training which learns to reconstruct its inputs via a discrete latent bottleneck and thereby effectively strips the latent representation of high-frequency details such as texture. Subsequently, we train an autoregressive transformer model to learn the distribution of the discrete image representations conditioned on a tokenized version of the layouts. Our experiments show that the resulting system is able to synthesize high-quality images consistent with the given layouts. In particular, we improve the state-of-the-art FID score on COCO-Stuff and on Visual Genome by up to 19% and 53% and demonstrate the synthesis of images up to 512 x 512 px on COCO and Open Images.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
Afifi, Mahmoud; Derpanis, Konstantinos G; Ommer, Björn; Brown, Michael S
Learning Multi-Scale Photo Exposure Correction Conference
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
@conference{6992,
title = {Learning Multi-Scale Photo Exposure Correction},
author = {Mahmoud Afifi and Konstantinos G Derpanis and Björn Ommer and Michael S Brown},
url = {https://github.com/mahmoudnafifi/Exposure_Correction
https://arxiv.org/abs/2003.11596},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
Kotovenko, Dmytro; Wright, Matthias; Heimbrecht, Arthur; Ommer, Björn
Rethinking Style Transfer: From Pixels to Parameterized Brushstrokes Conference
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
@conference{7041,
title = {Rethinking Style Transfer: From Pixels to Parameterized Brushstrokes},
author = {Dmytro Kotovenko and Matthias Wright and Arthur Heimbrecht and Björn Ommer},
url = {https://compvis.github.io/brushstroke-parameterized-style-transfer/
https://arxiv.org/abs/2103.17185},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
abstract = {There have been many successful implementations of
neural style transfer in recent years. In most of these works,
the stylization process is confined to the pixel domain. How-
ever, we argue that this representation is unnatural because
paintings usually consist of brushstrokes rather than pixels.
We propose a method to stylize images by optimizing parameterized brushstrokes instead of pixels and further introduce
a simple differentiable rendering mechanism.
Our approach significantly improves visual quality and en-
ables additional control over the stylization process such as
controlling the flow of brushstrokes through user input.
We provide qualitative and quantitative evaluations that
show the efficacy of the proposed parameterized representation.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
neural style transfer in recent years. In most of these works,
the stylization process is confined to the pixel domain. How-
ever, we argue that this representation is unnatural because
paintings usually consist of brushstrokes rather than pixels.
We propose a method to stylize images by optimizing parameterized brushstrokes instead of pixels and further introduce
a simple differentiable rendering mechanism.
Our approach significantly improves visual quality and en-
ables additional control over the stylization process such as
controlling the flow of brushstrokes through user input.
We provide qualitative and quantitative evaluations that
show the efficacy of the proposed parameterized representation.
2020
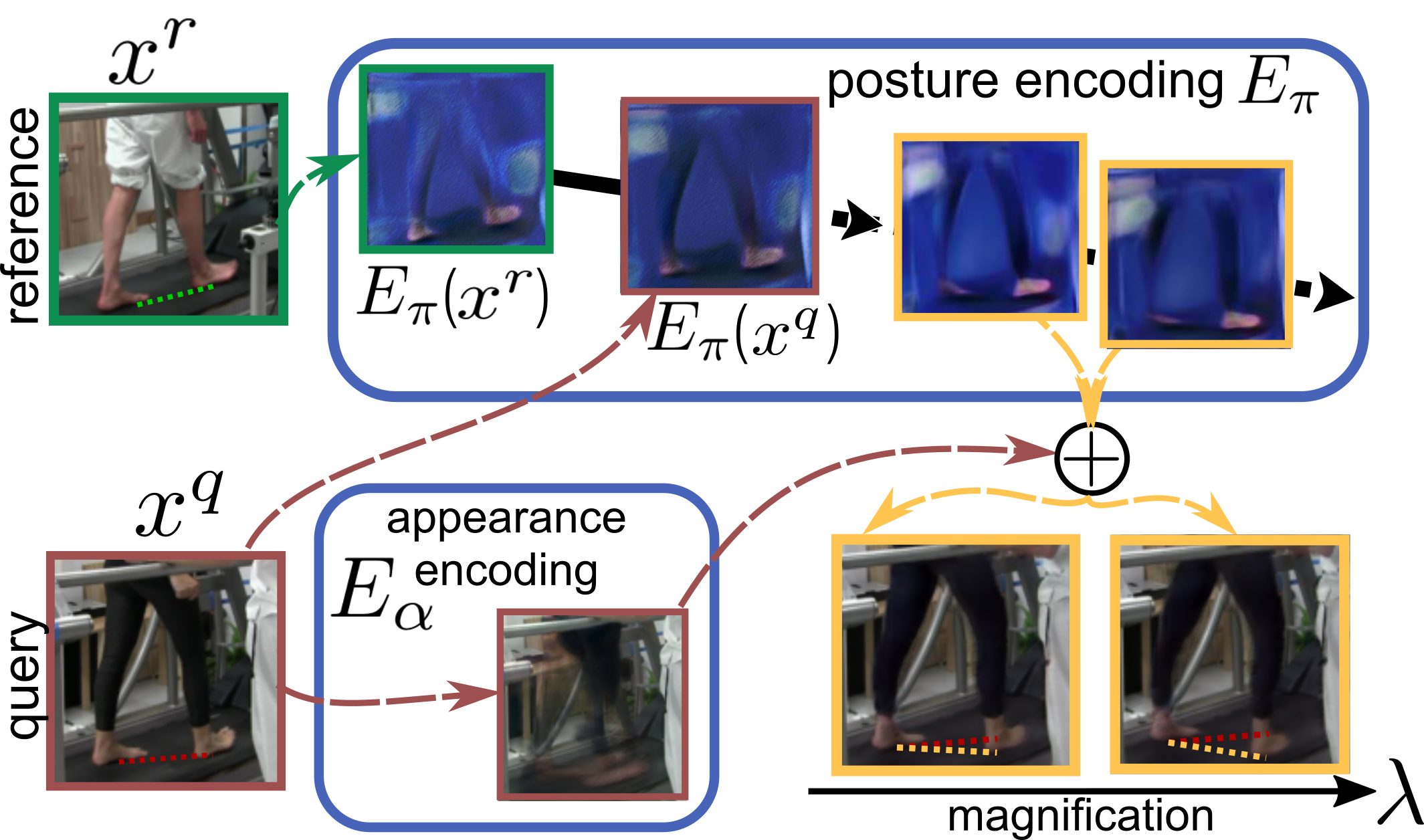
Dorkenwald, Michael; Büchler, Uta; Ommer, Björn
Unsupervised Magnification of Posture Deviations Across Subjects Conference
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
@conference{7042,
title = {Unsupervised Magnification of Posture Deviations Across Subjects},
author = {Michael Dorkenwald and Uta Büchler and Björn Ommer},
url = {https://compvis.github.io/magnify-posture-deviations/
https://openaccess.thecvf.com/content_CVPR_2020/papers/Dorkenwald_Unsupervised_Magnification_of_Posture_Deviations_Across_Subjects_CVPR_2020_paper.pdf},
year = {2020},
date = {2020-01-01},
urldate = {2020-01-01},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
Esser, Patrick; Rombach, Robin; Ommer, Björn
A Note on Data Biases in Generative Models Conference
NeurIPS 2020 Workshop on Machine Learning for Creativity and Design, 2020.
@conference{7025,
title = {A Note on Data Biases in Generative Models},
author = {Patrick Esser and Robin Rombach and Björn Ommer},
url = {https://neurips2020creativity.github.io/
https://arxiv.org/abs/2012.02516},
year = {2020},
date = {2020-01-01},
urldate = {2020-01-01},
booktitle = {NeurIPS 2020 Workshop on Machine Learning for Creativity and Design},
abstract = {It is tempting to think that machines are less prone to unfairness and prejudice. However, machine learning approaches compute their outputs based on data. While biases can enter at any stage of the development pipeline, models are particularly receptive to mirror biases of the datasets they are trained on and therefore do not necessarily reflect truths about the world but, primarily, truths about the data. To raise awareness about the relationship between modern algorithms and the data that shape them, we use a conditional invertible neural network to disentangle the dataset-specific information from the information which is shared across different datasets. In this way, we can project the same image onto different datasets, thereby revealing their inherent biases. We use this methodology to (i) investigate the impact of dataset quality on the performance of generative models, (ii) show how societal biases of datasets are replicated by generative models, and (iii) present creative applications through unpaired transfer between diverse datasets such as photographs, oil portraits, and animes.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
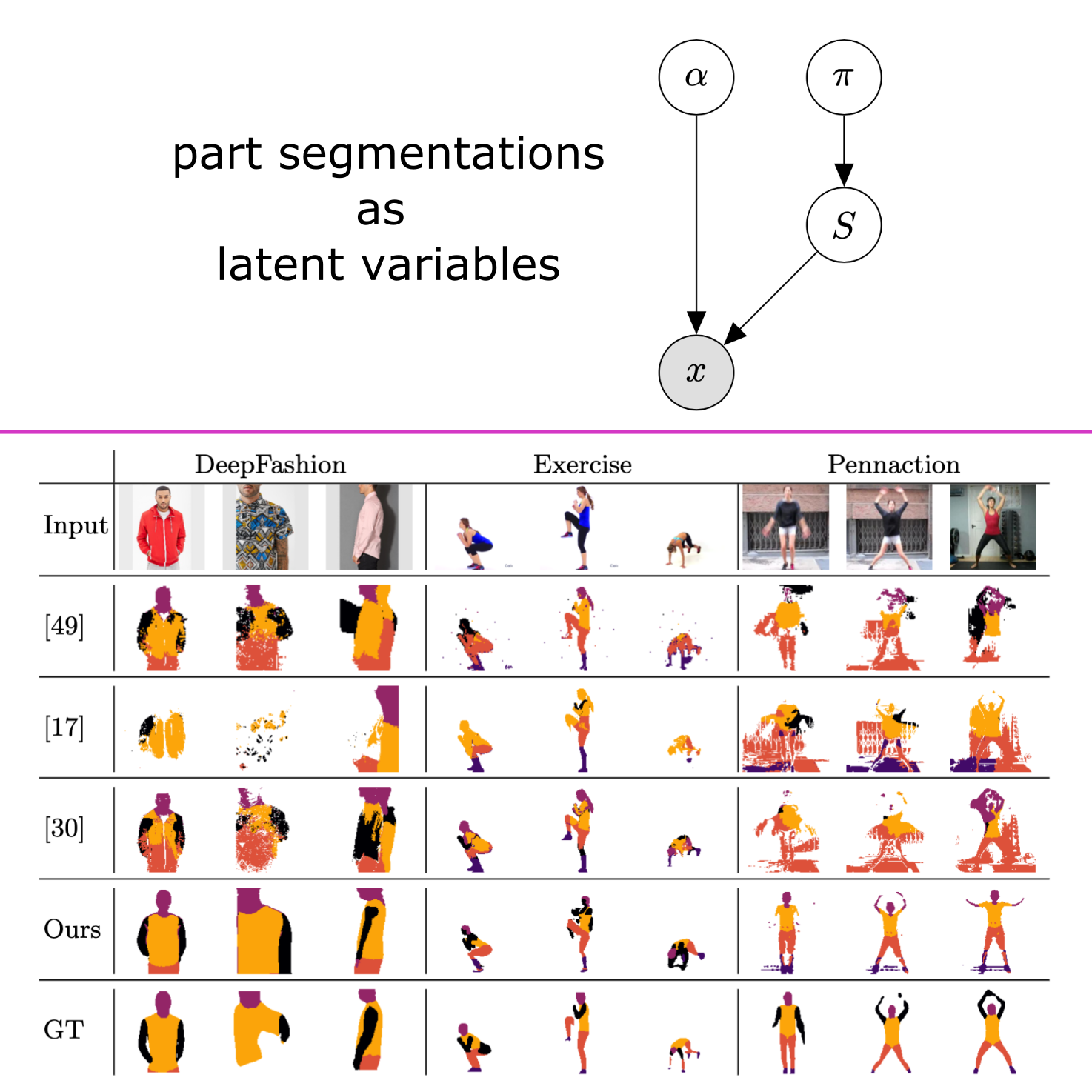
Braun, Sandro; Esser, Patrick; Ommer, Björn
Unsupervised Part Discovery by Unsupervised Disentanglement Conference
Proceedings of the German Conference on Pattern Recognition (GCPR) (Oral), Tübingen, 2020.
@conference{7004,
title = {Unsupervised Part Discovery by Unsupervised Disentanglement},
author = {Sandro Braun and Patrick Esser and Björn Ommer},
url = {https://compvis.github.io/unsupervised-part-segmentation/
https://arxiv.org/abs/2009.04264},
year = {2020},
date = {2020-01-01},
urldate = {2020-01-01},
booktitle = {Proceedings of the German Conference on Pattern Recognition (GCPR) (Oral)},
address = {Tübingen},
abstract = {We address the problem of discovering part segmentations of articulated objects without supervision. In contrast to keypoints, part segmentations provide information about part localizations on the level of individual pixels. Capturing both locations and semantics, they are an attractive target for supervised learning approaches. However, large annotation costs limit the scalability of supervised algorithms to other object categories than humans. Unsupervised approaches potentially allow to use much more data at a lower cost. Most existing unsupervised approaches focus on learning abstract representations to be refined with supervision into the final representation. Our approach leverages a generative model consisting of two disentangled representations for an objecttextquoterights shape and appearance and a latent variable for the part segmentation. From a single image, the trained model infers a semantic part segmentation map. In experiments, we compare our approach to previous state-of-the-art approaches and observe significant gains in segmentation accuracy and shape consistency. Our work demonstrates the feasibility to discover semantic part segmentations without supervision.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
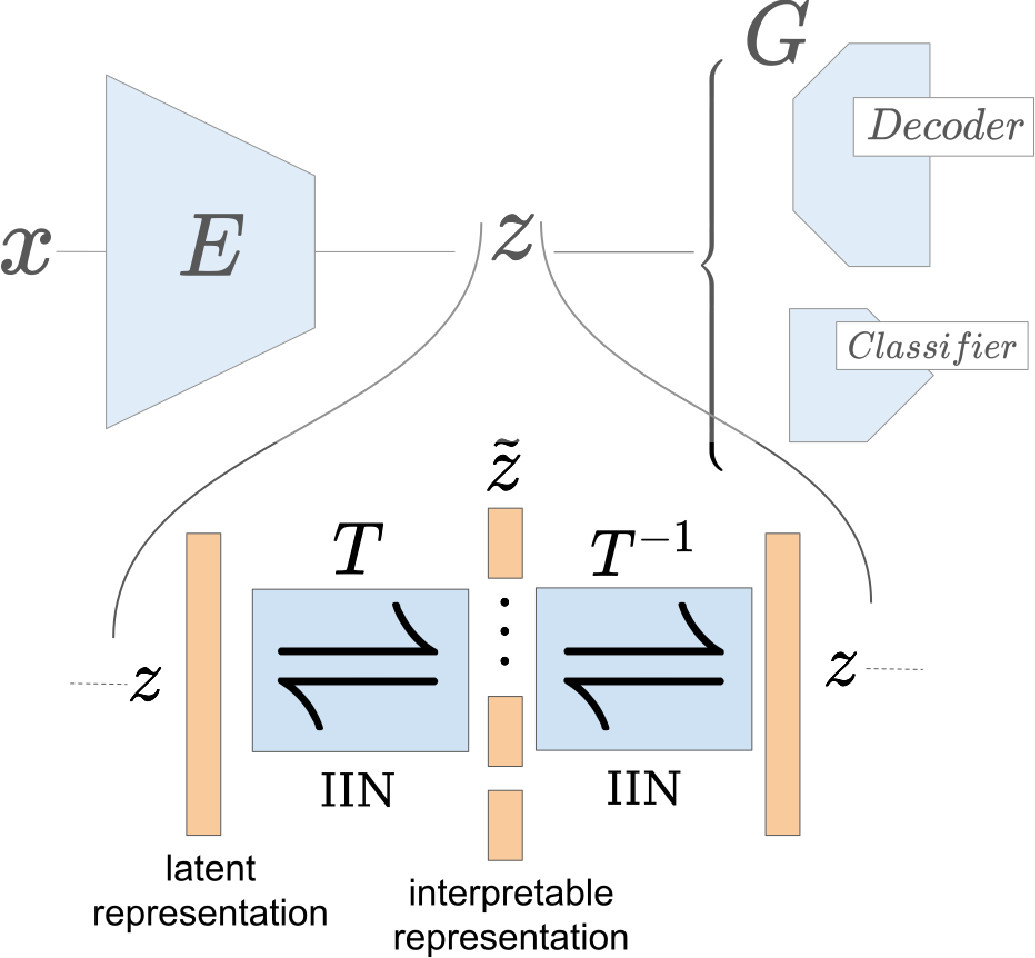
Esser, Patrick; Rombach, Robin; Ommer, Björn
A Disentangling Invertible Interpretation Network for Explaining Latent Representations Conference
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
@conference{6932,
title = {A Disentangling Invertible Interpretation Network for Explaining Latent Representations},
author = {Patrick Esser and Robin Rombach and Björn Ommer},
url = {https://compvis.github.io/iin/
https://arxiv.org/abs/2004.13166},
year = {2020},
date = {2020-01-01},
urldate = {2020-01-01},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
abstract = {Neural networks have greatly boosted performance in computer vision by learning powerful representations of input data. The drawback of end-to-end training for maximal overall performance are black-box models whose hidden representations are lacking interpretability: Since distributed coding is optimal for latent layers to improve their robustness, attributing meaning to parts of a hidden feature vector or to individual neurons is hindered. We formulate interpretation as a translation of hidden representations onto semantic concepts that are comprehensible to the user. The mapping between both domains has to be bijective so that semantic modifications in the target domain correctly alter the original representation. The proposed invertible interpretation network can be transparently applied on top of existing architectures with no need to modify or retrain them. Consequently, we translate an original representation to an equivalent yet interpretable one and backwards without affecting the expressiveness and performance of the original. The invertible interpretation network disentangles the hidden representation into separate, semantically meaningful concepts. Moreover, we present an efficient approach to define semantic concepts by only sketching two images and also an unsupervised strategy. Experimental evaluation demonstrates the wide applicability to interpretation of existing classification and image generation networks as well as to semantically guided image manipulation.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
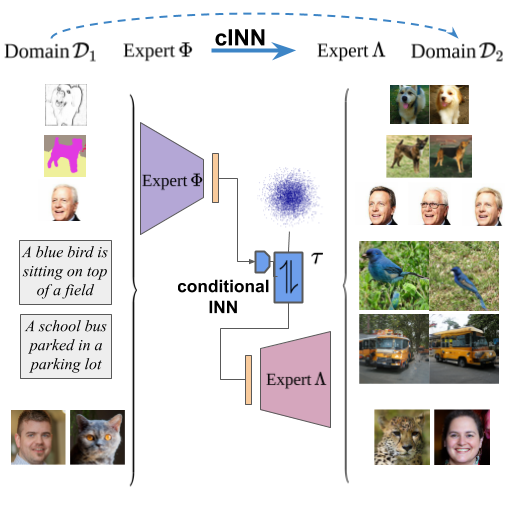
Rombach, Robin; Esser, Patrick; Ommer, Björn
Network Fusion for Content Creation with Conditional INNs Conference
CVPRW 2020 (AI for Content Creation), 2020.
@conference{7012,
title = {Network Fusion for Content Creation with Conditional INNs},
author = {Robin Rombach and Patrick Esser and Björn Ommer},
url = {https://compvis.github.io/network-fusion/
https://arxiv.org/abs/2005.13580},
year = {2020},
date = {2020-01-01},
urldate = {2020-01-01},
booktitle = {CVPRW 2020 (AI for Content Creation)},
abstract = {Artificial Intelligence for Content Creation has the potential to reduce the amount of manual content creation work significantly. While automation of laborious work is welcome, it is only useful if it allows users to control aspects of the creative process when desired. Furthermore, widespread adoption of semi-automatic content creation depends on low barriers regarding the expertise, computational budget and time required to obtain results and experiment with new techniques. With state-of-the-art approaches relying on task-specific models, multi-GPU setups and weeks of training time, we must find ways to reuse and recombine them to meet these requirements. Instead of designing and training methods for controllable content creation from scratch, we thus present a method to repurpose powerful, existing models for new tasks, even though they have never been designed for them. We formulate this problem as a translation between expert models, which includes common content creation scenarios, such as text-to-image and image-to-image translation, as a special case. As this translation is ambiguous, we learn a generative model of hidden representations of one expert conditioned on hidden representations of the other expert. Working on the level of hidden representations makes optimal use of the computational effort that went into the training of the expert model to produce these efficient, low-dimensional representations. Experiments demonstrate that our approach can translate from BERT, a state-of-the-art expert for text, to BigGAN, a state-of-the-art expert for images, to enable text-to-image generation, which neither of the experts can perform on its own. Additional experiments show the wide applicability of our approach across different conditional image synthesis tasks and improvements over existing methods for image modifications.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
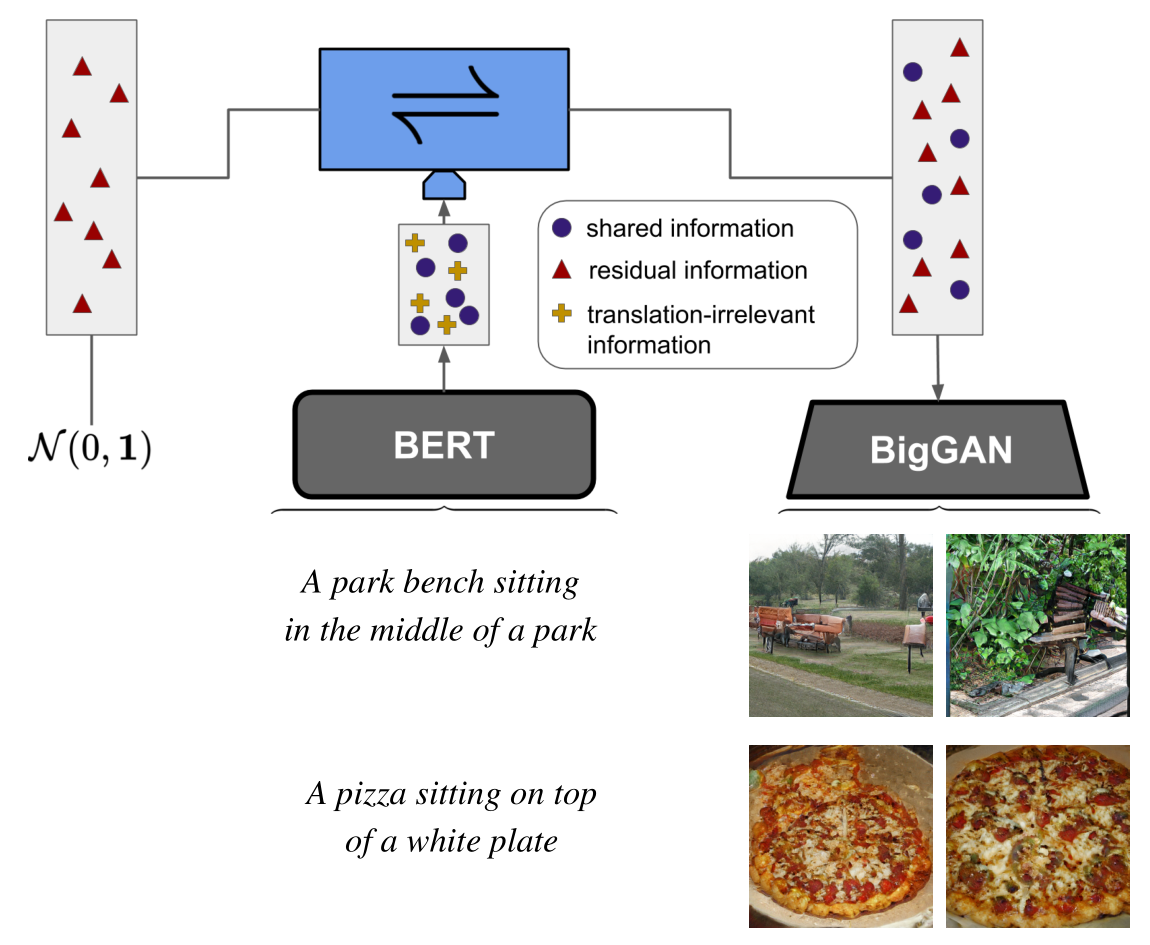
Rombach, Robin; Esser, Patrick; Ommer, Björn
Making Sense of CNNs: Interpreting Deep Representations & Their Invariances with INNs Conference
IEEE European Conference on Computer Vision (ECCV), 2020.
@conference{6997,
title = {Making Sense of CNNs: Interpreting Deep Representations & Their Invariances with INNs},
author = {Robin Rombach and Patrick Esser and Björn Ommer},
url = {https://compvis.github.io/invariances/
https://arxiv.org/pdf/2008.01777.pdf},
year = {2020},
date = {2020-01-01},
urldate = {2020-01-01},
booktitle = {IEEE European Conference on Computer Vision (ECCV)},
abstract = {To tackle increasingly complex tasks, it has become an essential ability of neural networks to learn abstract representations. These task-specific representations and, particularly, the invariances they capture turn neural networks into black box models that lack interpretability. To open such a black box, it is, therefore, crucial to uncover the different semantic concepts a model has learned as well as those that it has learned to be invariant to. We present an approach based on INNs that (i) recovers the task-specific, learned invariances by disentangling the remaining factor of variation in the data and that (ii) invertibly transforms these recovered invariances combined with the model representation into an equally expressive one with accessible semantic concepts. As a consequence, neural network representations become understandable by providing the means to (i) expose their semantic meaning, (ii) semantically modify a representation, and (iii) visualize individual learned semantic concepts and invariances. Our invertible approach significantly extends the abilities to understand black box models by enabling post-hoc interpretations of state-of-the-art networks without compromising their performance.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
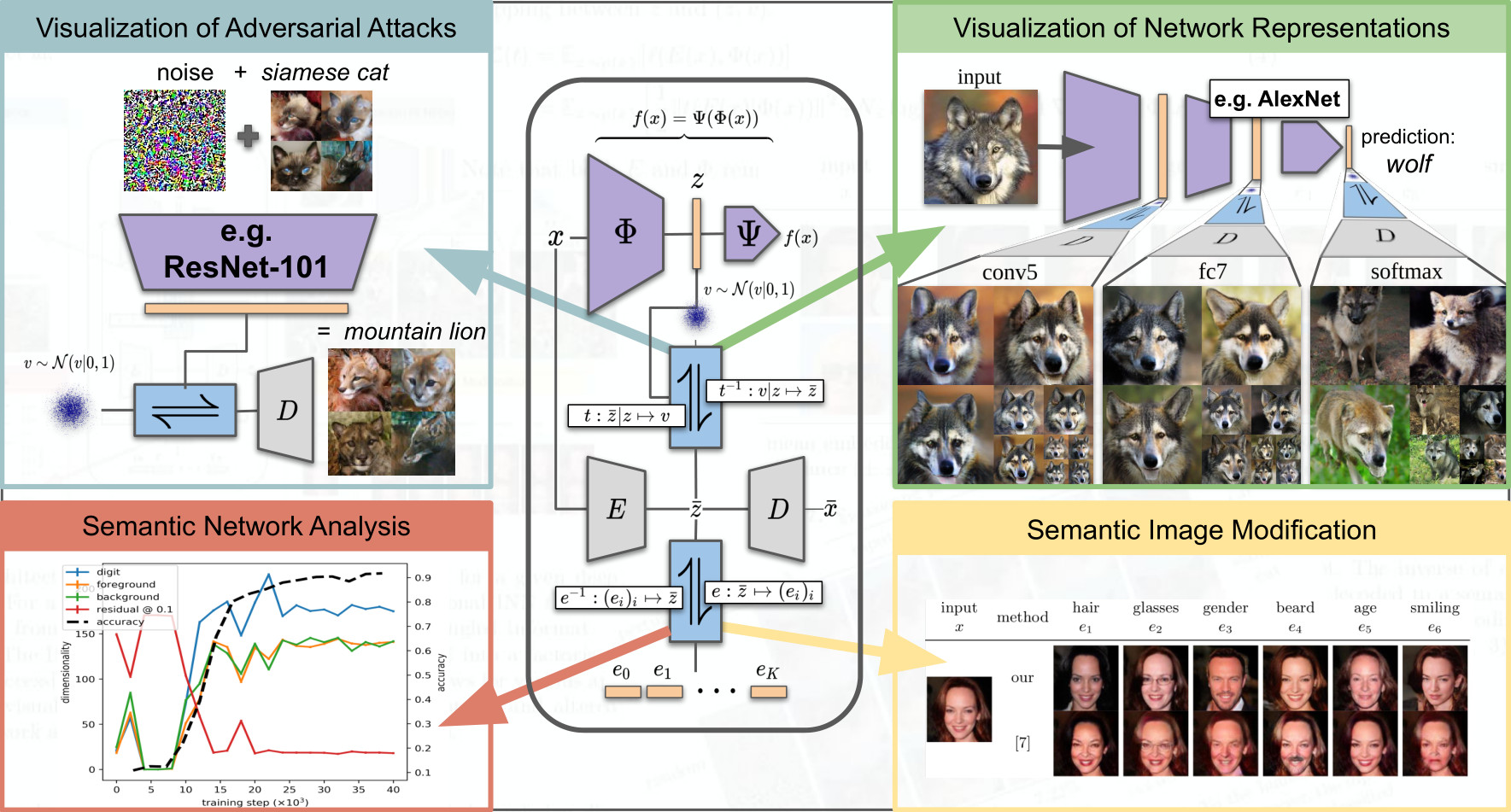
Rombach, Robin; Esser, Patrick; Ommer, Björn
Network-to-Network Translation with Conditional Invertible Neural Networks Conference
Neural Information Processing Systems (NeurIPS) (Oral), 2020.
@conference{7011,
title = {Network-to-Network Translation with Conditional Invertible Neural Networks},
author = {Robin Rombach and Patrick Esser and Björn Ommer},
url = {https://compvis.github.io/net2net/
https://arxiv.org/abs/2005.13580},
year = {2020},
date = {2020-01-01},
urldate = {2020-01-01},
booktitle = {Neural Information Processing Systems (NeurIPS) (Oral)},
abstract = {Combining stimuli from diverse modalities into a coherent perception is a striking feat of intelligence of evolved brains. This work seeks its analogy in deep learning models and aims to establish relations between existing networks by faithfully combining the representations of these different domains. Therefore, we seek a model that can relate between different existing representations by learning a conditionally invertible mapping between them. The network demonstrates this capability by (i) providing generic transfer between diverse domains, (ii) enabling controlled content synthesis by allowing modification in other domains, and (iii) facilitating diagnosis of existing representations by translating them into an easily accessible domain. Our domain transfer network can translate between fixed representations without having to learn or finetune them. This allows users to utilize various existing domain-specific expert models from the literature that had been trained with extensive computational resources. Experiments on diverse conditional image synthesis tasks, competitive image modification results and experiments on image-to-image and text-to-image generation demonstrate the generic applicability of our approach. In particular, we translate between BERT and BigGAN, state-of-the-art text and image models to provide text-to-image generation, which neither of both experts can perform on their own.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
2019
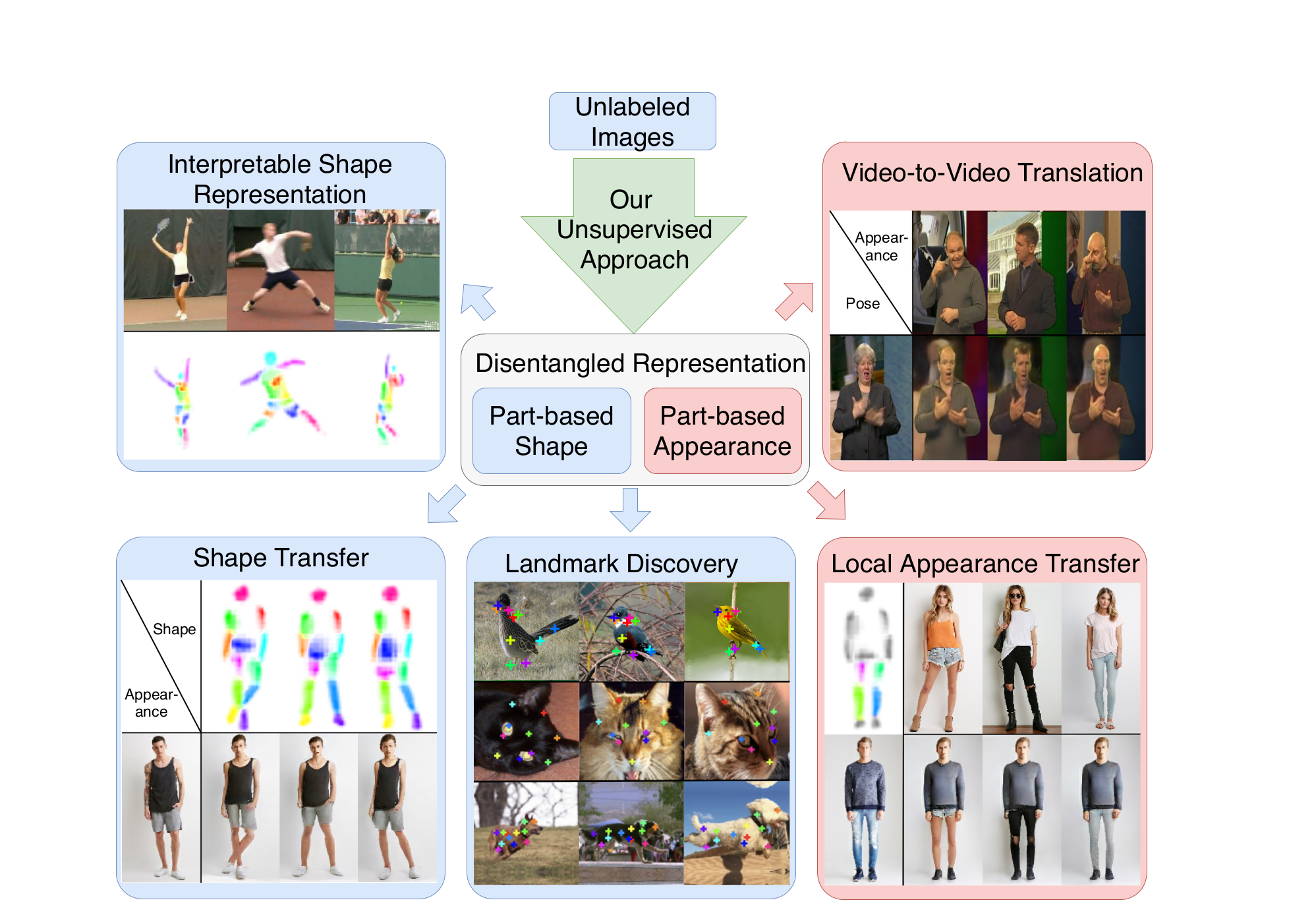
Lorenz, Dominik; Bereska, Leonard; Milbich, Timo; Ommer, Björn
Unsupervised Part-Based Disentangling of Object Shape and Appearance Conference
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Oral + Best paper finalist: top 45 / 5160 submissions), 2019.
@conference{6301,
title = {Unsupervised Part-Based Disentangling of Object Shape and Appearance},
author = {Dominik Lorenz and Leonard Bereska and Timo Milbich and Björn Ommer},
url = {https://compvis.github.io/unsupervised-disentangling/
https://arxiv.org/abs/1903.06946},
year = {2019},
date = {2019-01-01},
urldate = {2019-01-01},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Oral + Best paper finalist: top 45 / 5160 submissions)},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
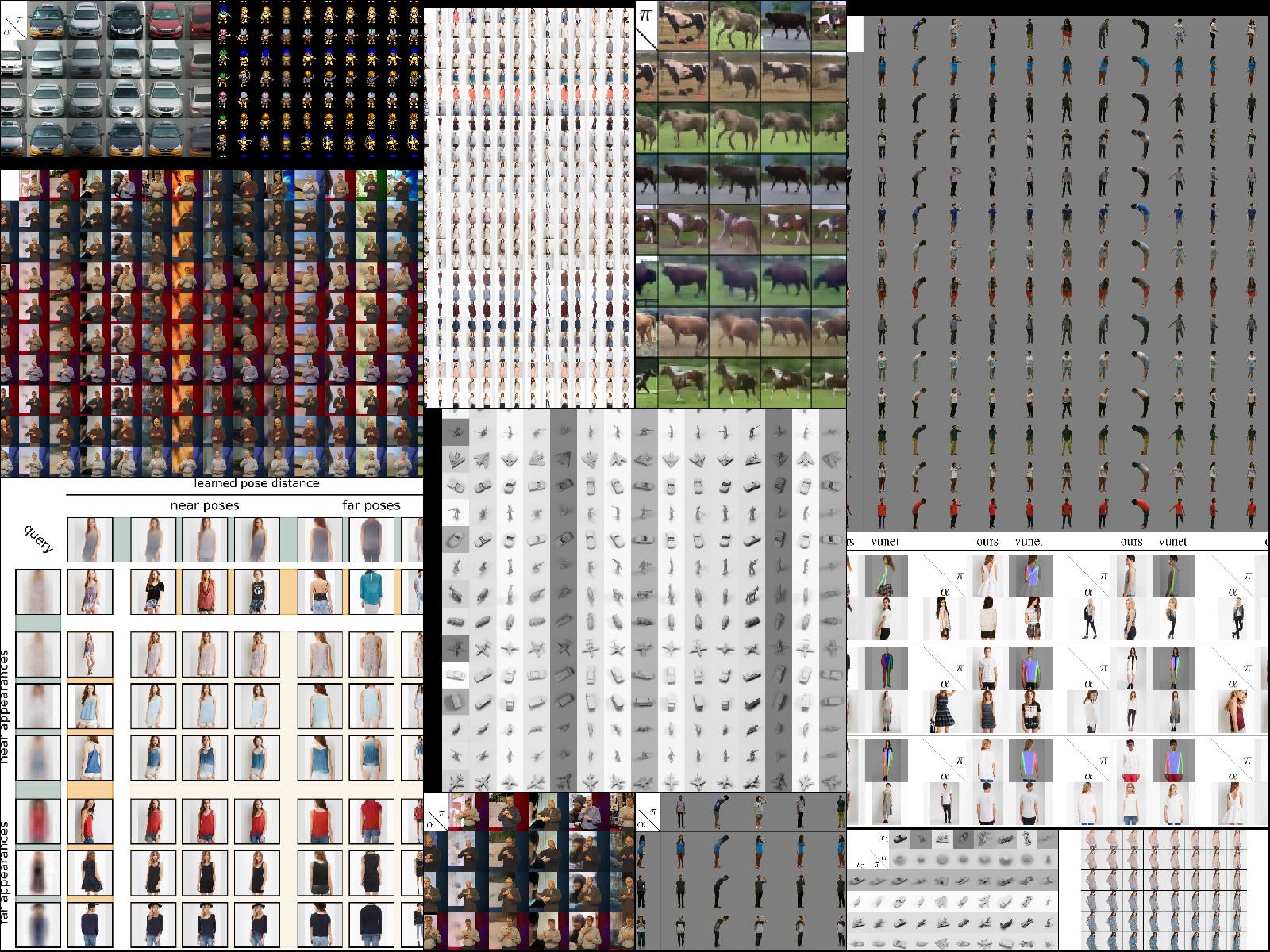
Esser, Patrick; Haux, Johannes; Ommer, Björn
Unsupervised Robust Disentangling of Latent Characteristics for Image Synthesis Conference
Proceedings of the Intl. Conf. on Computer Vision (ICCV), 2019.
@conference{6323,
title = {Unsupervised Robust Disentangling of Latent Characteristics for Image Synthesis},
author = {Patrick Esser and Johannes Haux and Björn Ommer},
url = {https://compvis.github.io/robust-disentangling/
https://arxiv.org/abs/1910.10223},
year = {2019},
date = {2019-01-01},
urldate = {2019-01-01},
booktitle = {Proceedings of the Intl. Conf. on Computer Vision (ICCV)},
abstract = {Deep generative models come with the promise to learn an explainable representation for visual objects that allows image sampling, synthesis, and selective modification. The main challenge is to learn to properly model the independent latent characteristics of an object, especially its appearance and pose. We present a novel approach that learns disentangled representations of these characteristics and explains them individually. Training requires only pairs of images depicting the same object appearance, but no pose annotations. We propose an additional classifier that estimates the minimal amount of regularization required to enforce disentanglement. Thus both representations together can completely explain an image while being independent of each other. Previous methods based on adversarial approaches fail to enforce this independence, while methods based on variational approaches lead to uninformative representations. In experiments on diverse object categories, the approach successfully recombines pose and appearance to reconstruct and retarget novel synthesized images. We achieve significant improvements over state-of-the-art methods which utilize the same level of supervision, and reach performances comparable to those of pose-supervised approaches. However, we can handle the vast body of articulated object classes for which no pose models/annotations are available.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
Kotovenko, Dmytro; Sanakoyeu, Artsiom; Lang, Sabine; Ommer, Björn
Content and Style Disentanglement for Artistic Style Transfer Conference
Proceedings of the Intl. Conf. on Computer Vision (ICCV), 2019.
@conference{6322,
title = {Content and Style Disentanglement for Artistic Style Transfer},
author = {Dmytro Kotovenko and Artsiom Sanakoyeu and Sabine Lang and Björn Ommer},
url = {https://compvis.github.io/content-style-disentangled-ST/
https://compvis.github.io/content-style-disentangled-ST/paper.pdf},
year = {2019},
date = {2019-01-01},
urldate = {2019-01-01},
booktitle = {Proceedings of the Intl. Conf. on Computer Vision (ICCV)},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
Kotovenko, Dmytro; Sanakoyeu, A.; Lang, Sabine; Ma, P.; Ommer, Björn
Using a Transformation Content Block For Image Style Transfer Conference
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
@conference{6300,
title = {Using a Transformation Content Block For Image Style Transfer},
author = {Dmytro Kotovenko and A. Sanakoyeu and Sabine Lang and P. Ma and Björn Ommer},
url = {https://compvis.github.io/content-targeted-style-transfer/
https://arxiv.org/abs/2003.08407},
year = {2019},
date = {2019-01-01},
urldate = {2019-01-01},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
2018

Esser, Patrick; Sutter, Ekaterina; Ommer, Björn
A Variational U-Net for Conditional Appearance and Shape Generation Conference
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (short Oral), 2018.
@conference{6249,
title = {A Variational U-Net for Conditional Appearance and Shape Generation},
author = {Patrick Esser and Ekaterina Sutter and Björn Ommer},
url = {https://compvis.github.io/vunet/
https://arxiv.org/abs/1804.04694},
year = {2018},
date = {2018-01-01},
urldate = {2018-01-02},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (short Oral)},
abstract = {Deep generative models have demonstrated great performance in image synthesis. However, results deteriorate in case of spatial deformations, since they generate images of objects directly, rather than modeling the intricate interplay of their inherent shape and appearance. We present a conditional U-Net for shape-guided image generation, conditioned on the output of a variational autoencoder for appearance. The approach is trained end-to-end on images, without requiring samples of the same object with varying pose or appearance. Experiments show that the model enables conditional image generation and transfer. Therefore, either shape or appearance can be retained from a query image, while freely altering the other. Moreover, appearance can be sampled due to its stochastic latent representation, while preserving shape. In quantitative and qualitative experiments on COCO, DeepFashion, shoes, Market-1501 and handbags, the approach demonstrates significant improvements over the state-of-the-art.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
Sanakoyeu, A.; Kotovenko, Dmytro; Lang, Sabine; Ommer, Björn
A Style-Aware Content Loss for Real-time HD Style Transfer Conference
Proceedings of the European Conference on Computer Vision (ECCV) (Oral), 2018.
@conference{style_aware_content_loss_eccv18,
title = {A Style-Aware Content Loss for Real-time HD Style Transfer},
author = {A. Sanakoyeu and Dmytro Kotovenko and Sabine Lang and Björn Ommer},
url = {https://compvis.github.io/adaptive-style-transfer/
https://arxiv.org/abs/1807.10201},
year = {2018},
date = {2018-01-01},
urldate = {2018-01-01},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV) (Oral)},
abstract = {Recently, style transfer has received a lot of attention. While much of this research has aimed at speeding up processing, the approaches are still lacking from a principled, art historical standpoint: a style is more than just a single image or an artist, but previous work is limited to only a single instance of a style or shows no benefit from more images. Moreover, previous work has relied on a direct comparison of art in the domain of RGB images or on CNNs pre-trained on ImageNet, which requires millions of labeled object bounding boxes and can introduce an extra bias, since it has been assembled without artistic consideration. To circumvent these issues, we propose a style-aware content loss, which is trained jointly with a deep encoder-decoder network for real-time, high-resolution stylization of images and videos. We propose a quantitative measure for evaluating the quality of a stylized image and also have art historians rank patches from our approach against those from previous work. These and our qualitative results ranging from small image patches to megapixel stylistic images and videos show that our approach better captures the subtle nature in which a style affects content.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
Blum, O.; Brattoli, Biagio; Ommer, Björn
X-GAN: Improving Generative Adversarial Networks with ConveX Combinations Conference
German Conference on Pattern Recognition (GCPR) (Oral), Stuttgart, Germany, 2018.
@conference{blum:GCPR:2018,
title = {X-GAN: Improving Generative Adversarial Networks with ConveX Combinations},
author = {O. Blum and Biagio Brattoli and Björn Ommer},
url = {https://ommer-lab.com/wp-content/uploads/2021/10/X-Gan_Improving-Generative-Adversarial-Networks-with-ConveX-Combinations.pdf
https://ommer-lab.com/wp-content/uploads/2021/10/xgan_supplementary.pdf
},
year = {2018},
date = {2018-01-01},
urldate = {2018-01-01},
booktitle = {German Conference on Pattern Recognition (GCPR) (Oral)},
address = {Stuttgart, Germany},
abstract = {Even though recent neural architectures for image generation are capable of producing photo-realistic results, the overall distributions of real and faked images still differ a lot. While the lack of a structured latent representation for GANs often results in mode collapse, VAEs enforce a prior to the latent space that leads to an unnatural representation of the underlying real distribution. We introduce a method that preserves the natural structure of the latent manifold. By utilizing neighboring relations within the set of discrete real samples, we reproduce the full continuous latent manifold. We propose a novel image generation network X-GAN that creates latent input vectors from random convex combinations of adjacent real samples. This way we ensure a structured and natural latent space by not requiring prior assumptions. In our experiments, we show that our model outperforms recent approaches in terms of the missing mode problem while maintaining a high image quality.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}