Visual Object Recognition in Datasets of Pre-Modern Images
Selected Publications
2011
Conference on Computer Vision and Image Analysis of Art II, vol. 7869, 2011.
2010
Recognition and Analysis of Objects in Medieval Images Conference
Proceedings of the Asian Conference on Computer Vision, Workshop on e-Heritage, Springer, 2010.
2009
Towards a Computer-based Understanding of Medieval Images Conference
Scientific Computing & Cultural Heritage, Springer, 2009.
Objectives
The main objectives of this research project are 1) to develop a tool for category-level object recognition of object categories such as crowns and swords in an image collection of medieval manuscripts 2) to identify different artistic workshops in the image collection 3) to develop a classification approach to label objects with artistic workshop and 4) to develop a system for ordering and interpolating between exemplars in an image collection.
Dataset
We have assembled a novel, annotated benchmark image dataset for cultural heritage from a corpus of 27 late medieval paper manuscripts, held by Heidelberg University Library. Produced between 1417 and 1477 in three important Upper German workshops, this corpus is rare in its magnitude and, in addition, offers an exceptional homogeneity concerning its date of origin, its provenance and its technical execution.
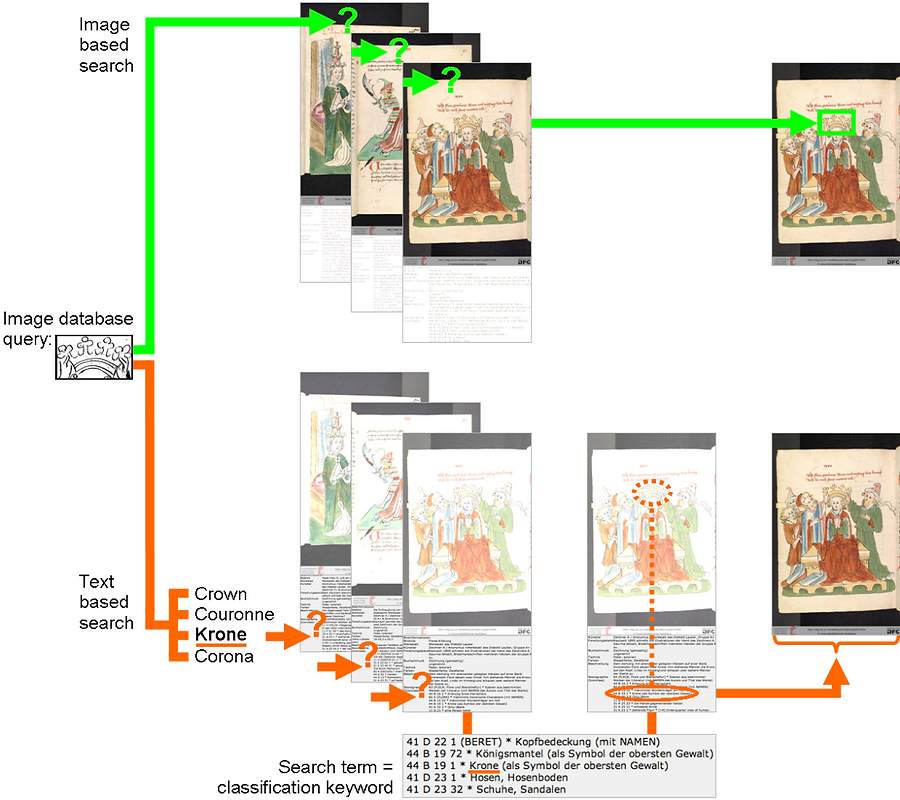
For a systematic access to large collections of images, it is necessary to develop algorithms that search the database based on the representational content of the images. For this, it is necessary to go beyond a mere analysis of individual image pixels onto a stage where the semantics of images can be modeled and analyzed. To make image databases accessible in a quicker, more reliable and detailed way, semantics based indexing is indeed necessary. The key for such algorithms is category level object detection.
Low Dimensional Embedding
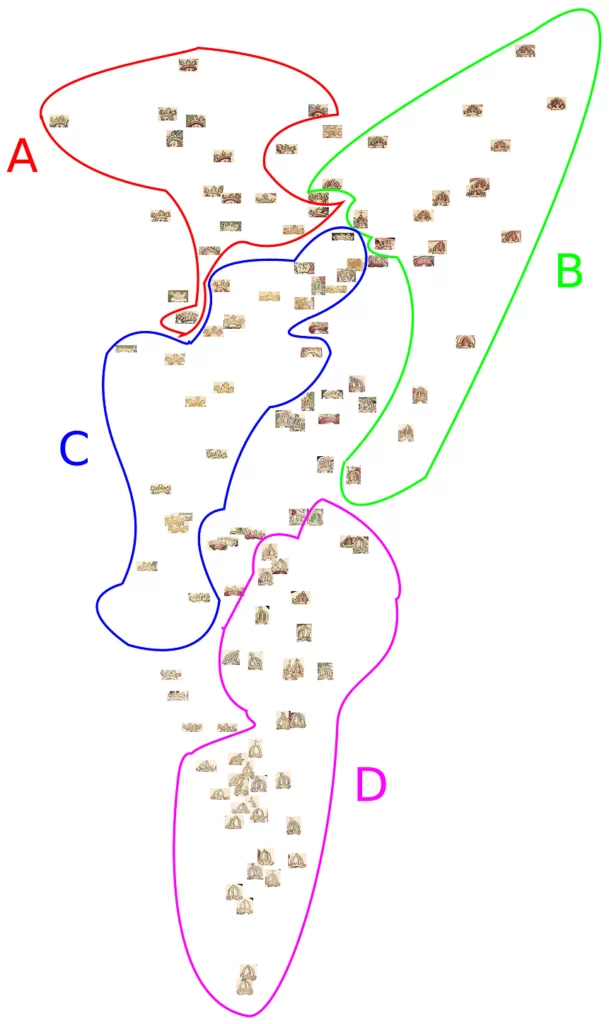
We utilize a shape based representation of objects since shape is an important cue in these medieval manuscripts. We have discovered from experiments that the images when represented in HSV color space, particularly the saturation component, provide a good starting point for object boundary extraction. We compute orientated edge histograms from the saturation component, which form the basis for our shape representation.
We capture the relationship between various object instances in the database in a single plot by embedding high dimensional edge orientation feature vectors into a 2-dimensional space. Such a plot makes it convenient for researchers from cultural heritage to discover relationships without having to study thousands of images. In a first step pairwise clustering based on HoG descriptors is employed to discover the hierarchical substructure of crowns. Then we compute the pairwise distances for samples in the vicinity of cluster prototypes. Thereafter, a distance preserving low-dimensional embedding is computed to project the high dimensional feature vectors onto a 2-d subspace that is visualized in the figure below.
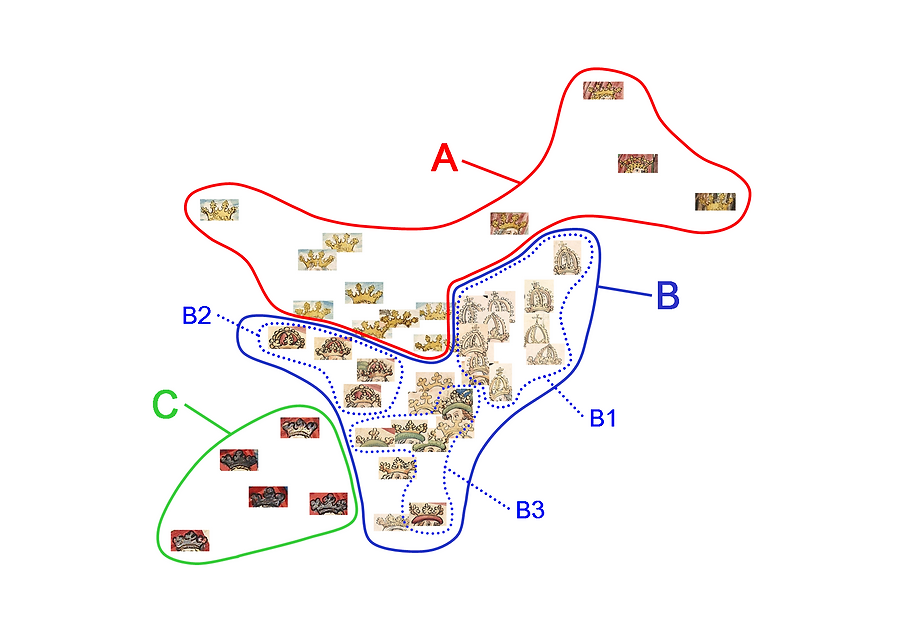
The above plot on the right displays two central findings of our system and thus reveal the potential of the approach: i) the high type-variability within a category and ii) the different principles of artistic design. In particular, our clusters for the category `crown’ show that to the simple crown circlet (A) varied elements like arches (B1), lined arches (B2), torus-shaped brims (B3), hats, or helmets are added. Thus, objects provide advanced semantic information concerning e.g. social hierarchies, which is not displayed by the common taxonomies. Since an automated image-based search does not suffer from the desiderata of annotation taxonomies, it becomes a crucial instrument to assist with the detailed differentiation of such subtypes, combining data from large numbers of images and organizing the compositional complexity of objects into a hierarchy of formal variants. Moreover, the clustering and visualization in a MDS-plot features different principles of artistic design, which are characteristic for different workshops engaged with the illustrations. Group (B) indicates the concise and accurate style, mainly based on definite contours, of the Hagenau workshop of Diebold Lauber, group (A) the more delicate and sketchy style of the Swabian workshop of Ludwig Henfflin, and group (C) the particular summary style of the so-called `Alsatian Workshop of 1418′. This detection of specific drawing styles is a highly relevant starting point to differentiate large-scale datasets by workshops, single teams within a workshop, or even by individual draftsmen.
Object recognition and Workshop Classification
Objects are detected by classifying image regions as object or background using a support vector machine with intersection kernel. This detection algorithm scans the image on multiple scales and orientations. Image regions are represented using the edge orientation shape representation and a color histogram. The necessary codebook of representative colors is obtained by first quantizing training image using minimum variance quantization into a set of 100 prototypical clusters per image. The bias towards large, homogenous regions is resolved by clustering all these prototypes into an overall set of 30 prototypical colors. Accurate localization of objects within the images makes complex representations like battle scenes or coronations with several symbols of power more easily readable. Textual annotations do not provide localization information so that object detection and reasoning about the spatial relationship between objects or about their performative context remains impossible. Based on the low dimensional embedding that we have generated as visualization, art historians have provided us with groundtruth information so that we can conduct a quantitative evaluation: they have labeled all crowns in the dataset with the workshop that they come from based on formal criteria. There are 137 crowns in our dataset that belong to group A (the workshop of Ludwig Henfflin), 106 crowns belong to group B (the workshop of Diebold Lauber) and 23 crowns belong to group C (the Alsatian workshop). We incorporated a discriminative approach for predicting the workshop that a crown belongs to. This multi-class classification problem is tackled using the features from before and incorporating SVM in a one-versus-all manner. For evaluation, we applied 10-fold cross-validation: In each round, 50% of the crowns from each group have been used for training and the remaining 50% of the crowns have been used for testing by holding back their labels. The confusion table below summarizes our classification performance.

Semi-Supervised Analysis
Given any two objects from a dataset the question arises how all the other objects in the database relate to these two exemplars. In particular, (i) can we find instances that help to interpolate between the selected reference exemplars, and (ii) can we order all those instances? Such an ordering is valuable for art history as it is directly visualizing relationships between the exemplars, it is illustrating smooth transitions in artistic style, and it could even reveal relationships between artists.
The low dimensional embedding plot which has helped the historians in visualizing the characteristics of different artistic workshops has a limitation. The completely unsupervised mapping from the high dimensional feature space to the 2-d space cannot preserve all the pairwise relationships between the crowns. This is an inherent limitation of any projection from higher dimensional feature space into a lower dimensional space that can be visualized. This limitation is particulary problematic for art historians when trying to infer the object relationship between crowns which belong to the same workshop, since these distances are more affected by the mapping. However,consider the following simple case. An arbitrary crown C has distances d1,d2 and d3 from three crowns CR 1,CR 2 and CR 3. Given the distance triplet (d1,d2,d3) we can assign 2-d locations to these four crowns such that the distances between C and CR 1,CR 2 and CR 3 are preserved. In fact, if we fix the crowns CR 1,CR 2 and CR 3 as landmark crowns with respect to which we obtain the distance triplets, we can find a 2-d configuration of crowns such that all the distance triplets are preserved. This simple but important insight leads us to a semisupervised approach where the user can choose the landmark crowns, all the other crowns are projected into 2-d space preserving the distance triplets. We start by obtaining three landmark crowns provided as input by the user. In a first experiment, one crown from each workshop was provided as landmark. Next, we compute the distance triplets for the rest of the crowns in the database. Then we choose the location of the landmark crowns at the three corners of an equilateral triangle in 2-d space ( which we refer to as `probability simplex’ ) such that the side of the triangle is greater than the maximum of the distance triplet values. Next, we find a mapping for each of the crowns into the interior of probability simplex such that the distance of the crown from the three corners of the equilateral triangle is proportional to its pre-computed distance triplet (d1,d2,d3). The figure below shows the organization of crowns in a probability simplex.
Given two crowns from the probability simplex, we compute the geodesic between the crowns ( in this case, a straight line joining the two crowns in the probability simplex ). Next, we project the rest of the crowns onto this geodesic and measure the distances between the projections onto the geodesics and the instances themselves.
We retain the crowns with small distances. Then, we generate a one dimensional ordering of the crowns (as shown below) by showing the user selected crowns at the two ends of the geodesic and the retained crowns at the projected locations onto the geodesics. The figure shows an example where two pairs of crowns from Hagenau workshop were provided as user input. Notice that a smooth transition can be observed in the one-dimensional ordering of crowns in the example.